通过大量实战案例分解Netty中是如何解决拆包黏包问题的?
图怪兽_d3c9b823ca0faaff4827def1bc596a37_83299.png
TCP传输协议是基于数据流传输的,而基于流化的数据是没有界限的,当客户端向服务端发送数据时,可能会把一个完整的数据报文拆分成多个小报文进行发送,也可能将多个报文合并成一个大报文进行发送。
在这样的情况下,有可能会出现图3-1所示的情况。
- 服务端恰巧读到了两个完整的数据包 A 和 B,没有出现拆包/粘包问题;
- 服务端接收到 A 和 B 粘在一起的数据包,服务端需要解析出 A 和 B;
- 服务端收到完整的 A 和 B 的一部分数据包 B-1,服务端需要解析出完整的 A,并等待读取完整的 B 数据包;
- 服务端接收到 A 的一部分数据包 A-1,此时需要等待接收到完整的 A 数据包;
- 数据包 A 较大,服务端需要多次才可以接收完数据包 A。
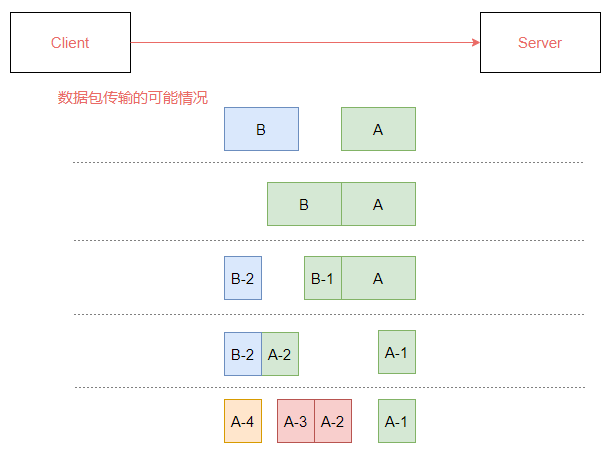
由于存在拆包/粘包问题,接收方很难界定数据包的边界在哪里,所以可能会读取到不完整的数据导致数据解析出现问题。
拆包粘包问题实战
下面演示一个拆包粘包问题
PackageNettyServer
public class PackageNettyServer { |
SimpleServerHandler
public class SimpleServerHandler extends ChannelInboundHandlerAdapter { |
PackageNettyClient
public class PackageNettyClient { |
SimpleClientHandler
public class SimpleClientHandler extends ChannelInboundHandlerAdapter { |
运行上述案例后,会出现粘包和拆包问题。
应用层定义通信协议
如何解决拆包和粘包问题呢?
一般我们会在应用层定义通信协议。其实思想也很简单,就是通信双方约定一个通信报文协议,服务端收到报文之后,按照约定的协议进行解码,从而避免出现粘包和拆包问题。
其实大家把这个问题往深度思考一下就不难发现,之所以在拆包粘包之后导致收到消息端的内容解析出现错误,是因为程序无法识别一个完整消息,也就是不知道如何把拆包之后的消息组合成一个完整消息,以及将粘包的数据按照某个规则拆分形成多个完整消息。所以基于这个角度思考,我们只需要针对消息做一个通信双方约定的识别规则即可。
消息长度固定
每个数据报文都需要一个固定的长度,当接收方累计读取到固定长度的报文后,就认为已经获得了一个完整的消息,当发送方的数据小于固定长度时,则需要空位补齐.
如图3-2所示,假设我们固定消息长度是4,那么没有达到长度的报文,需要通过一个空位来补齐,从而使得消息能够形成一个整体。

这种方式很简单,但是缺点也很明显,对于没有固定长度的消息,不清楚如何设置长度,而且如果长度设置过大会造成字节浪费,长度太小又会影响消息传输,所以一般情况下不会采用这种方式。
特定分隔符
既然没办法通过固定长度来分割消息,那能不能在消息报文中增加一个分割符呢?然后接收方根据特定的分隔符来进行消息拆分。比如我们采用\r\n来进行分割,如图3-3所示。

对于特定分隔符的使用场景中,需要注意分隔符和消息体中的字符不要存在冲突,否则会出现消息拆分错误的问题。
消息长度加消息内容加分隔符
基于消息长度+消息内容+分隔符的方式进行数据通信,这个之前大家在Redis中学习过,redis的报文协议定义如下。
*3\r\n$3\r\nSET\r\n$4\r\nname\r\n$3\r\nmic |
可以发现消息报文包含三个维度
- 消息长度
- 消息分隔符
- 消息内容
这种方式在项目中是非常常见的协议,首先通过消息头中的总长度来判断当前一个完整消息所携带的参数个数。然后在消息体中,再通过消息内容长度以及消息体作为一个组合,最后通过\r\n进行分割。服务端收到这个消息后,就可以按照该规则进行解析得到一个完整的命令进行执行。
Zookeeper中的消息协议
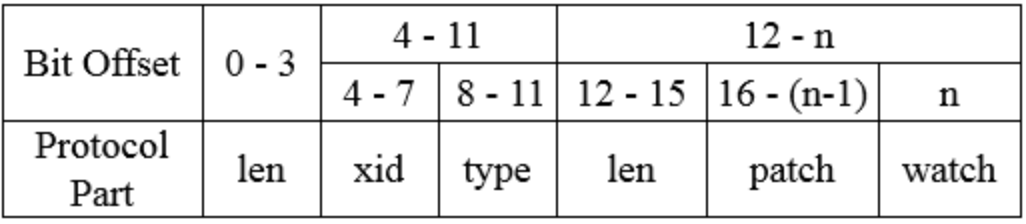
在Zookeeper中使用了Jute协议,这是zookeeper自定义消息协议,请求协议定义如图3-4所示。
xid用于记录客户端请求发起的先后序号,用来确保单个客户端请求的响应顺序。type代表请求的操作类型,常见的包括创建节点、删除节点和获取节点数据等。
协议的请求体部分是指请求的主体内容部分,包含了请求的所有操作内容。不同的请求类型,其请求体部分的结构是不同的。
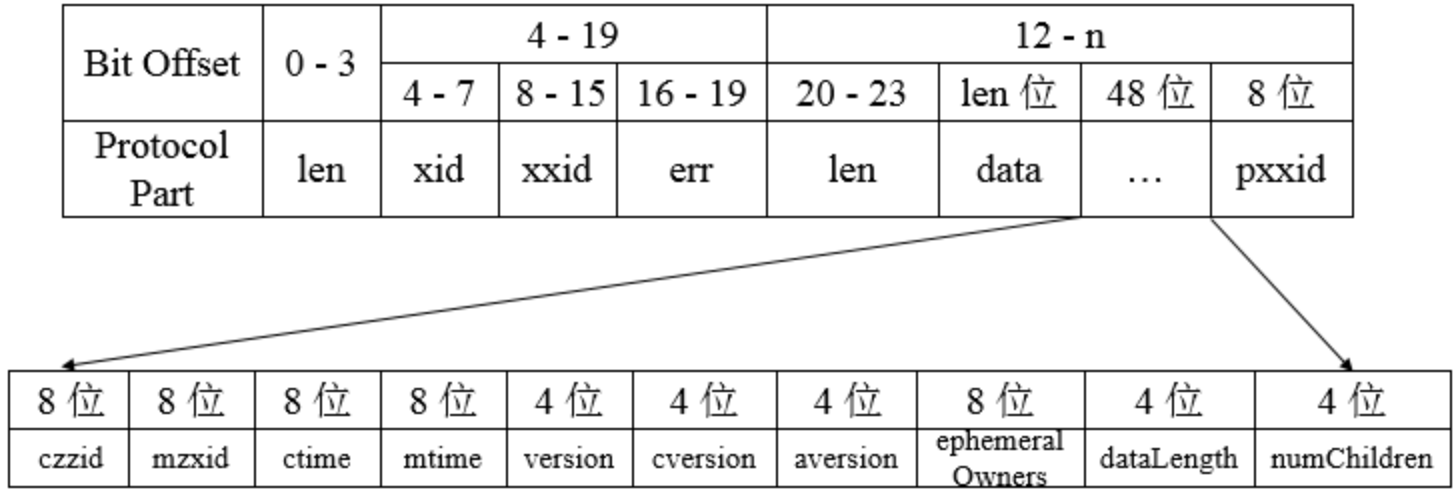
响应协议定义如图3-5所示。
协议的响应头中的xid和上文中提到的请求头中的xid是一致的,响应中只是将请求中的xid原值返回。zxid代表ZooKeeper服务器上当前最新的事务ID。err则是一个错误码,当请求处理过程中出现异常情况时,会在这个错误码中标识出来。协议的响应体部分是指响应的主体内容部分,包含了响应的所有返回数据。不同的响应类型,其响应体部分的结构是不同的。
Netty中的编解码器
在Netty中,默认帮我们提供了一些常用的编解码器用来解决拆包粘包的问题。下面简单演示几种解码器的使用。
FixedLengthFrameDecoder解码器
固定长度解码器FixedLengthFrameDecoder的原理很简单,就是通过构造方法设置一个固定消息大小frameLength,无论接收方一次收到多大的数据,都会严格按照frameLength进行解码。
如果累计读取的长度大小为frameLength的消息,那么解码器会认为已经获取到了一个完整的消息,如果消息长度小于frameLength,那么该解码器会一直等待后续数据包的达到,知道获得指定长度后返回。
使用方法如下,在3.3节中演示的代码的Server端,增加一个FixedLengthFrameDecoder,长度为10。
ServerBootstrap serverBootstrap=new ServerBootstrap(); |
DelimiterBasedFrameDecoder解码器
特殊分隔符解码器: DelimiterBasedFrameDecoder,它有以下几个属性
delimiters,delimiters指定特殊分隔符,参数类型是ByteBuf,ByteBuf可以传递一个数组,意味着我们可以同时指定多个分隔符,但最终会选择长度最短的分隔符进行拆分。
比如接收方收到的消息体为
hello\nworld\r\n
此时指定多个分隔符
\n和\r\n,那么最终会选择最短的分隔符解码,得到如下数据hello | world |
maxLength,表示报文的最大长度限制,如果超过maxLength还没检测到指定分隔符,将会抛出TooLongFrameException。
failFast,表示容错机制,它与maxLength配合使用。如果failFast=true,当超过maxLength后会立刻抛出TooLongFrameException,不再进行解码。如果failFast=false,那么会等到解码出一个完整的消息后才会抛出TooLongFrameException
stripDelimiter,它的作用是判断解码后的消息是否去除分隔符,如果stripDelimiter=false,而制定的特定分隔符是
\n,那么数据解码的方式如下。hello\nworld\r\n
当stripDelimiter=false时,解码后得到
hello\n | world\r\n
DecoderNettyServer
下面演示一下DelimiterBasedFrameDecoder的用法。
public class DecoderNettyServer { |
PrintServerHandler
定义一个普通的Inbound,打印接收到的数据。
public class PrintServerHandler extends ChannelInboundHandlerAdapter { |
演示方法
- 进入到cmd的命令窗口,执行telnet localhost 8080 回车
- 在telnet窗口按下
Ctrl+]组合键,进入到一个telnet界面 - 在该界面继续按回车,进入到一个新的窗口,这个时候可以开始输入字符,此时的命令窗口会带有数据回写。
- 开始输入字符 hello&world ,就可以看到演示效果
LengthFieldBasedFrameDecoder解码器
LengthFieldBasedFrameDecoder是长度域解码器,它是解决拆包粘包最常用的解码器,基本上能覆盖大部分基于长度拆包的场景。其中开源的消息中间件RocketMQ就是使用该解码器进行解码的。
首先来说明一下该解码器的核心参数
- lengthFieldOffset,长度字段的偏移量,也就是存放长度数据的起始位置
- lengthFieldLength,长度字段锁占用的字节数
- lengthAdjustment,在一些较为复杂的协议设计中,长度域不仅仅包含消息的长度,还包含其他数据比如版本号、数据类型、数据状态等,这个时候我们可以使用lengthAdjustment进行修正,它的值=包体的长度值-长度域的值
- initialBytesToStrip,解码后需要跳过的初始字节数,也就是消息内容字段的起始位置
- lengthFieldEndOffset,长度字段结束的偏移量, 该属性的值=lengthFieldOffset+lengthFieldLength
上面这些参数理解起来比较难,我们通过几个案例来说明一下。
消息长度+消息内容的解码
假设存在图3-6所示的由长度和消息内容组成的数据包,其中length表示报文长度,用16进制表示,共占用2个字节,那么该协议对应的编解码器参数设置如下。
- lengthFieldOffset=0, 因为Length字段就在报文的开始位置
- lengthFieldLength=2,协议设计的固定长度为2个字节
- lengthAdjustment=0,Length字段质保函消息长度,不需要做修正
- initialBytesToStrip=0,解码内容是Length+content,不需要跳过任何初始字节。

截断解码结果
如果我们希望解码后的结果中只包含消息内容,其他部分不变,如图3-7所示。对应解码器参数组合如下
- lengthFieldOffset=0,因为Length字段就在报文开始位置
- lengthFieldLength=2 , 协议设计的固定长度
- lengthAdjustment=0, Length字段只包含消息长度,不需要做任何修正
- initialBytesToStrip=2, 跳过length字段的字节长度,解码后ByteBuf只包含Content字段。

长度字段包含消息内容
如图3-8所示,如果Length字段中包含Length字段自身的长度以及Content字段所占用的字节数,那么Length的值为0x00d(2+11=13字节),在这种情况下解码器的参数组合如下
- lengthFieldOffset=0,因为Length字段就在报文开始的位置
- lengthFieldLength=2,协议设计的固定长度
- lengthAdjustment=-2,长度字段为13字节,需要减2才是拆包所需要的长度。
- initialBytesToStrip=0,解码后内容依然是Length+Content,不需要跳过任何初始字节

基于长度字段偏移的解码
如图3-9所示,Length字段已经不再是报文的起始位置,Length字段的值是0x000b,表示content字段占11个字节,那么此时解码器的参数配置如下:
- lengthFieldOffset=2,需要跳过Header所占用的2个字节,才是Length的起始位置
- lengthFieldLength=2,协议设计的固定长度
- lengthAdjustment=0,Length字段只包含消息长度,不需要做任何修正
- initialBytesToStrip=0,解码后内容依然是Length+Content,不需要跳过任何初始字节

基于长度偏移和长度修正解码
如图3-10所示,Length字段前后分别有hdr1和hdr2字段,各占据1个字节,所以需要做长度字段的便宜,还需要做lengthAdjustment的修正,相关参数配置如下。
- lengthFieldOffset=1,需要跳过hdr1所占用的1个字节,才是Length的起始位置
- lengthFieldLength=2,协议设计的固定长度
- lengthAdjustment=1,由于hdr2+content一共占了1+11=12字节,所以Length字段值(11字节)加上lengthAdjustment(1)才能得到hdr2+Content的内容(12字节)
- initialBytesToStrip=3,解码后跳过hdr1和length字段,共3个字节

解码器实战
比如我们定义如下消息头,客户端通过该消息协议发送数据,服务端收到该消息后需要进行解码

先定义客户端,其中Length部分,可以使用Netty自带的LengthFieldPrepender来实现,它可以计算当前发送消息的二进制字节长度,然后把该长度添加到ByteBuf的缓冲区头中。
public class LengthFieldBasedFrameDecoderClient { |
上述代码运行时,会得到两个报文。

下面是Server端的代码,增加了LengthFieldBasedFrameDecoder解码器,其中有两个参数的值如下
lengthFieldLength:2 , 表示length所占用的字节数为2
initialBytesToStrip: 2 , 表示解码后跳过length的2个字节,得到content内容
public class LengthFieldBasedFrameDecoderServer { |
总结
前面我们分析的几个常用解码器,只是帮我们解决了半包和粘包的问题,最终会让接受者收到一个完整有效的请求报文并且封装到ByteBuf中, 而这个报文内容是否有其他的编码方式,比如序列化等,还需要单独进行解析处理。
另外,很多的中间件,都会定义自己的报文协议,这些报文协议除了本身解决粘包半包问题以外,还会传递一些其他有意义的数据,比如zookeeper的jute、dubbo框架的dubbo协议等。